If it is awake, it will move. And if it moves, your images are likely to do it too. This means that, almost surely, the first step in processing your data will be to align (or register) all the images in the sequence. This is such a basic problem that there are probably as many solutions as readers of this blog, and I invite you to share yours in the comments below.
Below is our approach, which seems to work reasonably well. (At some later time I will discuss the possibility of doing this alignment in real-time as images are being acquired.)
Suppose we have a stack of images indexed 
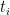

The general strategy consists in splitting the sequence in two sets, A and B. The set A holds the first half of the sequence and B the second half. Then, we recursively call our alignment function to register the set in A, which returns 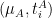

The final step is to find the transformation required to align the mean image of A with the mean image of B, 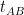

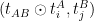

It turns that you can not only compute the mean recursively, but all the other moments as well. Thus, in a single pass through the data, the algorithm can align the images, and compute the mean, second, third and fourth moments of the aligned sequence. From there it is easy to compute the images corresponding to the variance, skewness and kurtosis of the distributions of the signal at each location.
Note the algorithm works for any class of transformations, but it helps to keep it simple. If you are using a resonant, two-photon microscope then, because of the relatively high rate of imaging the distortions from one frame to the next are well approximated by a simple translation. Feel free to try other transformations, but beware of the fact that you will pay a heavy prize in processing time.
The resulting code is only a few lines long:
function r = sbxalign(fname,idx)
if(length(idx)==1)
A = sbxread(fname,idx(1),1); % read the frame
S = sparseint; % sparse interpolant for...
A = squeeze(A(1,:,:))*S; % spatial correction of green channel
r.m{1} = A; % mean
r.m{2} = zeros(size(A)); % 2nd moment
r.m{3} = zeros(size(A)); % 3rd moment
r.m{4} = zeros(size(A)); % 4th moment
r.T = [0 0]; % no translation (identity)
r.n = 1; % # of frames
else
idx0 = idx(1:floor(end/2)); % split into two groups
idx1 = idx(floor(end/2)+1 : end);
r0 = sbxalign(fname,idx0); % align each group
r1 = sbxalign(fname,idx1);
[u v] = fftalign(r0.m{1},r1.m{1}); % align their means
for(i=1:4) % shift mean image and moments
r0.m{i} = circshift(r0.m{i},[u v]);
end
delta = r1.m{1}-r0.m{1}; % online update of the moments (read the Pebay paper)
na = r0.n;
nb = r1.n;
nx = na + nb;
r.m{1} = r0.m{1}+delta*nb/nx;
r.m{2} = r0.m{2} + r1.m{2} + delta.^2 * na * nb / nx;
r.m{3} = r0.m{3} + r1.m{3} + ...
delta.^3 * na * nb * (na-nb)/nx^2 + ...
3 * delta / nx .* (na * r1.m{2} - nb * r0.m{2});
r.m{4} = r0.m{4} + r1.m{4} + delta.^4 * na * nb * (na^2 - na * nb + nb^2) / nx^3 + ...
6 * delta.^2 .* (na^2 * r1.m{2} + nb^2 * r1.m{2}) / nx^2 + ...
4 * delta .* (na * r1.m{3} - nb * r0.m{3}) / nx;
r.T = [(ones(size(r0.T,1),1)*[u v] + r0.T) ; r1.T]; % transformations
r.n = nx; % number of images in A+B
end
The algorithm lends itself to parallel processing by enclosing the recursive calls (lines 22 and 23) in a parfor loop. However, the gains (or not) will depend largely on the disk array you have.
The optimal translation (with single pixel resolution) is found using FFTs:
function [u,v] = fftalign(A,B) N = min(size(A)); yidx = round(size(A,1)/2)-N/2 + 1 : round(size(A,1)/2)+ N/2; xidx = round(size(A,2)/2)-N/2 + 1 : round(size(A,2)/2)+ N/2; A = A(yidx,xidx); B = B(yidx,xidx); C = fftshift(real(ifft2(fft2(A).*fft2(rot90(B,2))))); [~,i] = max(C(:)); [ii jj] = ind2sub(size(C),i); u = N/2-ii; v = N/2-jj;
You can allow for more complex transformations by using Matlab’s imregtform but, I warn you once more, you will have to wait substantially longer. Remember that in a typical experiment you will be aligning tens of thousands of images (18,000 in the example below.)
So here is an example of the estimated translations along with the movement of the ball, which is obtained via a camera synchronized to the frames of the microscope. Not surprisingly, when the mouse runs there is relative movement detected in the estimated translation of the alignment.

Also note that the movement in at this magnification has an extent of about 5-6 pixels, this is comparable to the radius of a cell body. A typical result of aligning the images using this method is shown below, where you can still discern individual processes after a 20 min imaging session.

The outcome of the alignment is the mean image, along with the moments and the sequence of transformations. We do not store a new set of aligned images, as doing so would require much space. Instead, next time we read the image from the raw data file, if the alignment data is present, we can apply the alignment transformation so we can read the aligned stack.
What do you do? Do you have a different method to share?

Nice one!
The core alignment we do pretty much exactly the same. WIth the goal in mind to have this done immediately after each experiment (so far I did not dare to think of real-time – what;s your secret? FPGA?) I spent some time optimizing the FFTs. That’s where the code gets slow.
In the end I dumped all FFTs on my cheap gaming GPU. Instant 10fold speed increase (using the now defunct acelereyes matlab toolbox). The relative benefit, of course, depends on your array size – with your large pixelnumbers that should help a lot…
I just got a new Nvidia GTX Titan that should increase the spead ~|5 times further – maybe more since the RAM is much larger… I can post the code and the benchmarking later this week if there is interest.
Best,T
I have not tried doing the FFTs on the GPU… I thought the bottleneck would be in moving data around… I will benchmark some code next week and post the comparisons. As for real-time image stabilization — it is not that difficult. I will explain in a separate post…
i don’t get the claim that fast scanning means translation only, do you mean rigid only? — rotation is also an issue right? also, i don’t see any benefit in the recursive design — you implicitly choose the last image as the master to align everyone else to. if that were an unlucky choice you’re in trouble. why not choose the image that best correlates with the mean image, for example? it’s trivial to align everyone to it in “a single pass.” as long as i’m here, i am wondering why you chose to compete with (rather than contribute to) scanimage? and why the move to an fpga? what realtime analysis is too slow in normal software?
1 – The main advantage of the recursive design is that the code can be parallelized easily.
2 – In our hands, with GCamp6 we always have a subset of cells that are clearly visible throughout the image sequence that provide the structure required for alignment — so we do not see the problem you raise (the possibility that some frames are poor choices for alignment). An alternative we use sometimes is to align to the red channel when we have tdTomato.
3 – It is true that the movement is not purely translational (see https://scanbox.wordpress.com/2014/08/03/non-rigid-deformation-for-calcium-imaging-frame-alignment/), but in our hands the largest deformations are largely translations. (Perhaps brains cannot easily rotate?)
4 – This project was born form a request by a colleague to help get his microscope working. This was my introduction to the technique and I had no prior experience with Scanimage whatsoever. As I enjoy building my own instrumentation, and because it would allow us to modify it easily when we need it, I accepted the challenge. I hope some of the techniques and ideas we publish here can be incorporated in other systems.
5 – The Scanbox card is largely responsible for generating the timing needed for the hardware, it is not used to accelerate image processing (we use the GPU for that instead — as in the code for the nonrigid alignment posted in the link above).
er, processing each element in an array is trivial to parallelize, right?. in our prep, behavioral motor responses can induce rotational artifacts. they’re below imregcorr’s resolution (same fast phase correlation you use, right, but includes rotation). so i have to use a 6x slower imregtform/rigid. non-rigid is too general/slow for our case. can you speak to the relative tradeoffs scanbox makes vs scanimage? what aspects of hardware timing wouldn’t have just worked with a typical nidaq card? thanks for the info!
We sample 2 PMT channels for every laser pulse (at 80Mhz) — see https://scanbox.wordpress.com/2014/03/18/synchronize-to-the-laser/. I am not sure if there is a NI PXI card that will do it… perhaps… but with the need of chassis and everything else it would be an expensive choice.
I am afraid I don’t really know how Scanimage5 works exactly so I can’t offer a comparison. Here is their site — http://vidriotechnologies.com/?page_id=124